Sometimes you receive an Excel report or an export from another system with a lot of empty cells in a category column:
If you want to analyze the data, either with a Pivot table or with formulas such as SUMIFS and VLOOKUP, you need to populate all the empty cells in the category (dimension) columns, in this example column A.
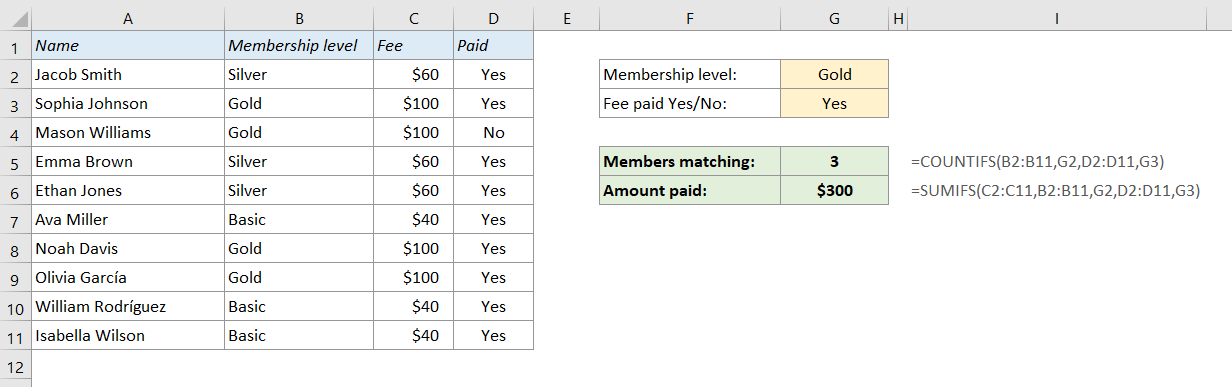
For example, if you want the Total Sales for Northeast, the formula =SUMIFS(E:E,A:A,”Northeast”) will only work if you have the right region in every cell in column A .
This is how you do it:
READ MORE